- Home
- /
- Programming
- /
- Developers
- /
- Re: Failed to transcode data from U_UTF8_CE to U_LATIN1_CE
- RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
gingyu, It is amazing how easy and far you are doing with this not easy SAS challenges. Not being mindblocked, solving each topic one by one in multitasking mode.
That /tmp location is the default for a Unix temporary files (Posix Linux apology as I use the old AT name) . I do not kow how many users you have on the system and what your options are for file-systems and storage. You could extend the /tmp filesystem but as it is the common for all tmp files on the machines may not the best way. You could set up some new mountpoints like:
/var/local/sas/tmpusr -> for personal users the workspace server appserver
/var/local/sas/tmpbtch -> for shared operations batch processing of an it-operations like
SAS(R) 9.4 System Options: Reference, Third Edition (work)
/var/local/sas/tmputl -> for the interenal tmporary files of Proc sql, proc sort. These filesnames are named #UTL.... normally invisible
SAS(R) 9.4 System Options: Reference, Third Edition (utillloc)
You do not possible need all of them it is only for loadbalancing having multiple users/processes running on the system
Every mountpoint/filesystem can be setup with enough space (Unix administration) for your intended processing. Any idea of your biggest datset sizing you will proces? make it at least 4 times bigger than that. (I forgot) set the acces rights on those directory like /tmp. A chmod of 3777 or 3770 will do setting the sticky bit and groupid bit. If a group access can be used to limit others can left out.
Check those filesystems when running out of space. Regular Cleanup of workfiles can be automated (using cron) later, something to park in your mind now.
Having those filesystems in your unix you can point to them using the sas-config-files. (Lev-/SASApp\sasv9_usermods.cfg). dedicated nested one can be used to give a SP or batch-server an other work-location
-work /var/local/sas/tmpusr
-utilloc /var/local/sas/tmputl

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
I appreciate your patient.I benefit greatly from you.
Thanks a lot!
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
I have solved that error.
Now I can create a new table in SASwork,but when I analyse the data like this:
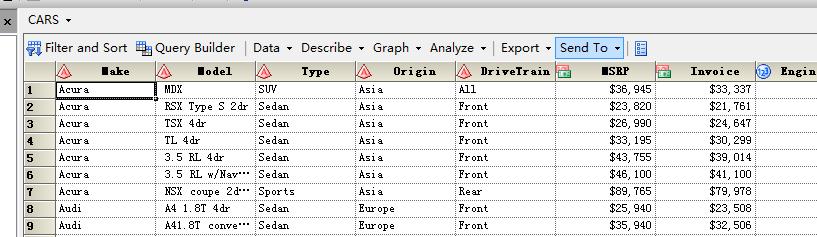
There is a error existing all the time.The error is :
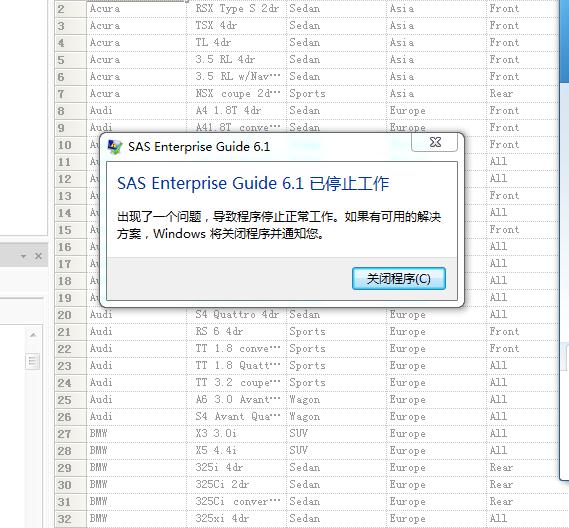
Then the client of SAS Enterprise Guide will shutdown.I doubt the error is something wrong about the configuration of " -utilloc /var/local/sas/tmputl ".How to slove the error?()
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Hi,my friend:
I have a new problem about SAS Metadata Server.When I restart the Metadata Server,The error is like following picture:

So I check the logs.I am told that the disk is full or the quota has been exceeded.

this is my filesystem and the storage of /dev/sda2 is full.So I wanna ask how to solve this problem?

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Gingyu, This question is a more difficult one not for the technical questions, but by its concepts wit all involved uncertainties.
The maximum of Users is very dependent on a lot of factors. The used Hardware, type of SAS usage, optimizations performance/tuning.
Testing of your implementation how it is performing can be seen as something as kind of regression testing. When planning for a kind of service you should set some kind of benchmark dedicated for your type of service.
Hardware:
You started with an installation and are asking now what it could serve. It is an approach workable in a new environment. In an existing environment you are knowing some of the usage and with that an sizing and than start with the sizing and tuning of the hardware (memory cpu io) with the operating system (OS). Clustering and Grid to be evaluated as options.
SAS usage:
There are several types of usage:
- I interactive The classic information consumers running some known "sas application"
- B batch The classic data processing as executed by an operations support staff. t strategy (Agile waterfall)
- D descriptive adhoc analytics It is the BI part for the next question to answer or self-service BI
- M data/etxt mining
note:
I,B will use a Develop/Test/Acceptance/Production (DTAP) release managemen
D,M will not use the classic DTAP as it developed with production data. There will be a need to segregate
I,D are by nature executed in office hours.
B,M can be scheduled less or more to run outside office hours.
Every usage type can be divided to some ordinals of resources usage:
- light
- medium
- heavy
- extra ordinary
It is about memory/cpu/io and expected runs active at the same moment with a response-time and the DBMS load.
With interactive light-usage there will be a small probability of parallel running. By this you can support a lot of users.
Extra ordinary data mining on the other can be that very demanding that running a couple of uses can exhaust the same machine.
It is good to know about the existence of cgroups - Wikipedia, the free encyclopedia. It is kernel change where it is made possible to do load balancing. It is rather new and not yet accepted as common practice in the Linux world.
By this you have a 4*4 matrix of resource usage with some expectations with assumptions to be filled in.
Knowing the load capacity of your machine/configuration you can set some predictions on the expected load with users.
It will be a continuous measuring and refining to optimize this model. Changing a badly build "sas application" can move that one from heavy to light. To do such things is balancing cost/effort. As you see there will be no fixed defined way how to work at this load cost change performance area.
Resource usage:
Knowing your environment it should be easy to design some tests that will easily overload you machine.
Using Eguide (starting with 5.1) or SAS/connect (MP connect) you can start by yourself a lot of task's in parallel.
Running the same or slightly change code you can get some impression on the performance.
Simple tests:
- Running a proc sort on some faked generated data will cause a heavy load on IO and/or memory using cpu.
having the sizing parameterized you can do this for 1G 10G 20G 50Gb 100Gb sizes dataset. And do this for 1-10 jobs in parallel.
For sure the machine should get overloaded at some moment.
- For the DBMS you can imagine some of the same making difference between reading the DBMS and writing the DBMS
- (more)
You probably did not tuned your SAS options. Sumsize (proc means) memsize bufsize aligniofiles. Some of them will have impact on the bigger data processing.
In a multiuser system it is nor very sensible to give all memory to one process. You can run into http://en.wikipedia.org/wiki/Thrashing_(computer_science).
Connecting to your dbms think on: defer=yes bulkload bufsize. The OS (tcpip) is tuned for 4k block others often for the 64K block sizes.
There is some choice to make, I am used to go for data processing for bigger data, accepting causing some overhead for the smaller ones.
As example a faked dataset, easy to modify to your own ideas. This faked dataset in uncompressed setting is about 1Kb/record. Using the compress=binary is a good tip for datasets having more data fields. If would suggest using an array of 256 character variables 8 bytes long with some random content.
data ivp_run.tst1 ;
length tekst $1024;
do i=1 to &sizenum ;
var1=I; var2=ranuni(10000) ; tekst="äsb 1234567890 qwerty" ; output;
end;
run;
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Hi it's me again.
As your answer about changing the SASWork.I faced a new error;
I have defined follows:
/CUBEDATA/LVCUBDAT1/SAS/SASHome/tmpusr
/CUBEDATA/LVCUBDAT1/SAS/SASHome/tmputl
tmpusr file contains:
/CUBEDATA/LVCUBDAT1/SAS/SASHome/sastempfiles
method=space
tmputl file contains:
/CUBEDATA/LVCUBDAT1/SAS/SASHome/sastempfiles
method=space
Have written into Lev-/SASApp\sasv9_usermods.cfg
-work /CUBEDATA/LVCUBDAT1/SAS/SASHome/tmpusr
-utilloc /CUBEDATA/LVCUBDAT1/SAS/SASHome/tmputl
and restart the SAS servers.
But the error is like following pictures:


- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
You have defined:
/CUBEDATA/LVCUBDAT1/SAS/SASHome/tmpusr
/CUBEDATA/LVCUBDAT1/SAS/SASHome/tmputl
These should be visible and accessible using the key/account for your workspace server.
The modifications are only for SASApp that is the WS/SP services (running by sasssrv , personal account ).
The Object spawner and metadataserver are untouched not needing any restart.
You are getting an error that is telling you something is wrong having done that change. Now we need to find what is wrong.
1/ switch to that personal account and verify
+ you can go into that directory every directory in de hierarchy should at least have x access (group/others) seeing the content needing r-access(group/others).
There are a lot of people "security specialist" not knowing the x right is indicating you are able to do the "cd" command. That is needed for the whole hierarchy:
= /CUBEDATA
= /CUBEDATA/LVCUBDAT1
= /CUBEDATA/LVCUBDAT1/SAS
= /CUBEDATA/LVCUBDAT1/SAS/SASHome
= /CUBEDATA/LVCUBDAT1/SAS/SASHome/tmpwrk
+ create new files directories there (tmpwrk).
The chmod rights (do a ls -la) should be 3770 of 3777 (rwxrws--T rwxrwsrwt)
Those letters s and t are no typos, they are comin from the Gid-bit setting (that 2 first of 4 digits) and sticky-bit settings (that 1 giving 3 first of 4 digits).
That gid-bit will cause the group inheritance from the directory, not the first group associated with the active key
That sticky bit will cause onely the owner of the file or the owner of the directory are able to delete files. This is by default set on "/tmp"
There are a lot of people "security specialist" not knowing this.
As you can create files there with a restricted personal key, than you have validate this.
2/ double check the spelling of all the directory names. Unix is case-sensitive. Every spelling with a caps/nocaps difference is a real difference.
As this is different in Windows and in SAS (as long it is SAS language specific) this can be a behavioral pitfall.
IT could be a typo somewhere, check the name using the output of "pwd" command with the SAS-config modification in the SASApp
3/ You could use some terminal access using sas to verify basic settings. It is only doable when you are good in sas knowing all of that basic modes.
he sas Linux-script can be manually started,
- it will try the dms interface using x11. You will need a x11-server for that.
- with the options -nodms -noterminal it will start a line-mode interface showing a number where you can put a sas-statement. "endsas; " is the statement toe leave that.
You can leave you Eguide open and there is no need for restarting the objectspawner/metdataserver.
As long you have the error there will be no connection. Watch the processes being started by you when you get the connection
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
I am sorry but I cannot read that error message. The Chinese language is just Chinese for me.:smileyblush:
I need someone that will do the translation.
The checking of sasutl can be done in the same way as saswrk. as it used later (proc sql / sort) It will not block your sas session but cause a run time error.
For a check you leave it out. IT will default to the same location as saswork. It is one to do for performance and resource isolation.
Are all checks ok on the ssh level and sas is running well without it in the config. Put in and check again. With some bigger sorts or sql you it should show activity there.
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Well there a lot of file systems full.
You can either add space or delete some things.
Look at your logfiles they are set up by default in the same as the config folders. As they are not cleaned they can fill up your system.
Another is the metadata backup folders, by default several copies are kept and I do not know the cleansing policy. They can fill up your system.
For those metadata backup folders do not delete them until yoy are sure how to repair your current version.
This default placing of logfiles and within the config folders is not the most reliable one for minimizing the full error conditions and the related monitoring to prevent that.
Improvements on that can be made but should be done carefully.
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
My SAS was not installed in the root filesystem.
It was installed in /dev/sdb1 like the third picture.
I doubt that there was something existing in the root files system(like /tmp) when restarting the Metadata Server.
Is anything existing on root file system("/") when restarting the Metadata Server ?
Can I redirect all configurations which was default just like what was done on SASWork?
Then how to do that ?
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Check your /tmp it is temporary. It can get filled by a lot of processes. It is the default sas is using during the installation and may be more.
Unix is having a convention for his hfs see: Filesystem Hierarchy Standard - Wikipedia, the free encyclopedia As being a convention you do not need to follow that it is just good practice to do so.
There are a lot of folders with some dedicated meaning /tmp /home /opt /etc /var
for /tmp (default system work) you have the split up of saswork on a different mountpoint (/var/saswrk?). it cannot interference with /tmp anymore
for /home you could do that as /home (default unix system keys) /home/usrgrp1/<key> a split up s this mountpoint cannot interference with the system ones
for /opt it are less or more stable types (not changing often) for installing applications. sas can be seen as a TI-application.
this is according: /opt (The Linux Documentation Project)
This one should have a dedicated mountpoint (or more) by that isolating it for all the rest,
for /var (variable data) you see log-files
This one should have a dedicated mountpoint (or more) by that isolating it for all the rest,
If you read this than you can see SAS institute is putting a lot of rubbish in that SAS-config mapping. Process logging user databases user coding/programs all getting mixed up.
I do not understand why do not follow the ideas of mountpoints and common Unix namings, that is something they should answer. (tlpd.org refrences)
The possible most harmfull are all those loggings. You can redirect (logical link) / rename those to an other location eg /var/opt/saslog and put a own mountpoint on that.
the dec/sdb1 is pointing to the name cubedata/lvcubdat1 94% more the association for cubes and not the sas software. that one is not full.
I guess it is /tmp or /var being in problems. You have to validate that.
Just adding the not fhs:
Linux Directory Hierarchy: Oriented to the Software Parts
The FHS is part of the LSB (Linux Standard Base), which makes him a good thing because all the industry is moving thowards it, and is a constant preoccupation to all distributions. FHS defines in which directories each peace of Apache, Samba, Mozilla, KDE and your Software must go, and you don't have any other reason to not use it while thinking in developing your Software, but I'll give you some more:
FHS is a standard, and we can't live without standards
- This is the most basic OS organization, that are related to access levels and security, where users intuitively find each type of file, etc
- Makes user's life easyer
This last reason already justifies FHS adoption, so allways use the FHS !!!
More about FHS importance and sharing the same directory structure can be found in Red Hat website.
- « Previous
-
- 1
- 2
- Next »

Don't miss out on SAS Innovate - Register now for the FREE Livestream!
Can't make it to Vegas? No problem! Watch our general sessions LIVE or on-demand starting April 17th. Hear from SAS execs, best-selling author Adam Grant, Hot Ones host Sean Evans, top tech journalist Kara Swisher, AI expert Cassie Kozyrkov, and the mind-blowing dance crew iLuminate! Plus, get access to over 20 breakout sessions.
Learn how use the CAT functions in SAS to join values from multiple variables into a single value.

Find more tutorials on the SAS Users YouTube channel.
 Click image to register for webinar
Click image to register for webinar
Classroom Training Available!
Select SAS Training centers are offering in-person courses. View upcoming courses for:
-
25 replies
-
09-09-2014 11:35 PM
-
22424 views
-
6 likes
-
3 in conversation
-
