- Home
- /
- Analytics
- /
- SAS Data Science
- /
- EM Gradient Boosting unable to produce a model
- RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
I ran Gradient Boosting in EM and only get single value prediction, p_sales = 0.8, but Regression, NN, and DT all produce a model. What goes wrong?
Accepted Solutions

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Open the Gradient Boosting node results and click on
View --> SAS Results --> Log
to view the log from your Gradient Boosting node and look for notes similar to the following:
...
NOTE: Will not search for split on variable A.
NOTE: Too few acceptable cases.
NOTE: Option MINCATSIZE=5 may apply.
NOTE: Will not search for split on variable B.
NOTE: Too few acceptable cases.
NOTE: Option MINCATSIZE=5 may apply
....
We have seen that message appear when some of the samples had an insufficient number of events and non-events and Gradient Boosting was unable to iterate. Sampling is used at different points to determine split values, and then the model is fit to the whole data set. If there are not enough events, then SAS Enterprise Miner cannot determine where the splits should occur.
Are other models able to run such as a regression model or decision tree? If so, examine your regression results to see whether there are many near-zero standard errors. Some customers have the opposite problem - infinite standard errors. For more information about this problem, please review
Usage Note 22599: Understanding and correcting complete or quasi-complete separation problems
http://support.sas.com/kb/22/599.html
Another possibility is that there are too many missing values in the data, or that the missing values are distributed in such a way that no splits can be found with the existing settings. Some options, depending on what you think is appropriate, might include:
- examining your imputed data to see whether it looks like you think it should look
- in the Gradient Boosting node, try:
- lowering the Minimum Categorical Size property to 2 or 3
- changing the Missing Values property
I hope this helps!
Doug

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Hey Aha,
What does the subseries plot for the Gradient Boosting node look like?
When you say Reg, NN, DT produce a model, how good of a model?
You might need to tweak the splitting rule or node options of the Gradient Boosting. Are you using the defaults? What have you moved around?
I hope it helps,
Miguel
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Subseries plot just contains one point.
Reg, NN, DT models all look normal and good.
I used teh defaults.
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
After I changed Leaf Fraction from 0.1 to 0.05, it was able to produce a model instead of a single value prediction. I see top important variables have high # of splitting rules in the Variable Importance window like 98. Will this change cause overfitting?
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Great job on tweaking your Gradient Boosting model!
The best way to confirm there is no overfitting is to take a look at the subseries plot. If the selected model is at a low point, no overfitting is expected.
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Can you elaborate on what you mean by "the selected model is at a low point"?
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
In my humble experience with real data I found it difficult to get overtrained models with gradient boosting. My guess is that the stochastic gradient descent function somehow prevent your model from getting overtrained the way you can overtrain a decision tree or other models.
What I run into a lot of times is something like the below. Increasing the number of steps does not necessarily mean lower ASE or misclassification. Adding steps do not necessarily get you a better model, but you are not getting a worse one either.
Look at the ASE of the training, it looks like it is going lower and lower, while in reality the ASE of the validation is not decreasing as you add iteration steps.
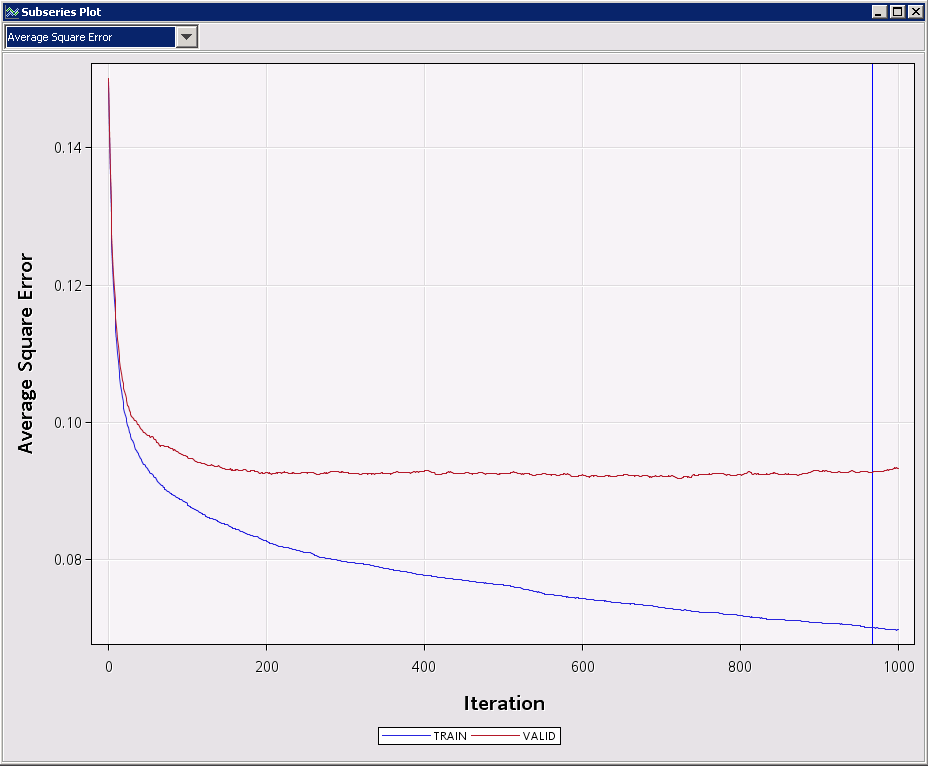
By "selecting a model at a low point" I mean that a good model seems to be in the region before it starts decreasing into a monotonical line. In my personal opinion it does not seem that it hurts the model to add a large number of iteration steps, but I haven't seen big gains either.
Now that you got your GB node to split, experiment a bit with and without a Partition node. Although you are not getting exactly the same models you should see a similar behavior.
Gradient Boosting models take a while to run but I have found that they really pay off as they are robust in the presence of new data, and they are also well suited for data with rare target events.
I hope it helps,
Miguel
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Thanks for the clarification!
I am not familiar with all theories behind Gradient Boosting. Can I create several gradient boosting nodes, twist parameters for each one and pick the best model? Will this way really give me the best model? Will using ensemble node to combine these GB nodes produce an even better model?
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
A great book that can catch you up in decision tree ensembles (including boosting and gradient boosting) is Decision Trees for Analytics Using SAS® Enterprise Miner™. In just a few pages you get most info you need on tree ensembles. By far my favorite SAS book of 2013!
Ensembles will give you a better model as long as the models are discordant, since probabilites get averaged. There is one example in this paper (http://support.sas.com/resources/papers/proceedings14/SAS133-2014.pdf) that talks about discordant models into a better ensemble model. Discordance is mentioned in the Decision Tree book too. Unfortunately there is no way to know if the ensemble will help, but running it.
Sounds like you have made good progress with your EM diagram. Keep up the good work!
Best,
Miguel

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Even I am facing the same problem. Gradient boosting node is not able to produce any model, no plots,no variable importance. Though it ran successfully.
I changed the following in default options:
Max Depth: 10
Surrogate rule: 2
The decision tree is running fine, but not gradient boosting.

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Were you able to solve this problem? I am facing the exact same issue while working with GBM
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Open the Gradient Boosting node results and click on
View --> SAS Results --> Log
to view the log from your Gradient Boosting node and look for notes similar to the following:
...
NOTE: Will not search for split on variable A.
NOTE: Too few acceptable cases.
NOTE: Option MINCATSIZE=5 may apply.
NOTE: Will not search for split on variable B.
NOTE: Too few acceptable cases.
NOTE: Option MINCATSIZE=5 may apply
....
We have seen that message appear when some of the samples had an insufficient number of events and non-events and Gradient Boosting was unable to iterate. Sampling is used at different points to determine split values, and then the model is fit to the whole data set. If there are not enough events, then SAS Enterprise Miner cannot determine where the splits should occur.
Are other models able to run such as a regression model or decision tree? If so, examine your regression results to see whether there are many near-zero standard errors. Some customers have the opposite problem - infinite standard errors. For more information about this problem, please review
Usage Note 22599: Understanding and correcting complete or quasi-complete separation problems
http://support.sas.com/kb/22/599.html
Another possibility is that there are too many missing values in the data, or that the missing values are distributed in such a way that no splits can be found with the existing settings. Some options, depending on what you think is appropriate, might include:
- examining your imputed data to see whether it looks like you think it should look
- in the Gradient Boosting node, try:
- lowering the Minimum Categorical Size property to 2 or 3
- changing the Missing Values property
I hope this helps!
Doug
.jpg")
Catch up on SAS Innovate 2026
Nearly 200 sessions are now available on demand with the SAS Innovate Digital Pass.
Explore Now →Use this tutorial as a handy guide to weigh the pros and cons of these commonly used machine learning algorithms.

Find more tutorials on the SAS Users YouTube channel.
-
11 replies
-
05-25-2014 10:30 PM
-
9666 views
-
1 like
-
5 in conversation
-
