- Home
- /
- Analytics
- /
- SAS Data Science
- /
- What is in a group variable from a variable selection node?
- RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Hello there,
I am having an issue with variable selection nodes which is wrecking my head I was hoping someone could give me a heads-up on this.
Say that I have a data set for used cars and my target is a binary called SOLD (0=no, 1=yes).
In my data set I have a nominal variable called COLOUR, where I have about 20 different colours (blue, black, silver, mustard, red, etc).
So I end up creating a variable selection node, and after I run it, the node set my COLOUR to not be used, in favour of a group variable it created named G_COLOUR.
So far so good. Here is what is wrecking my head... Say I add a decision tree after my variable selection node. Then I run this tree and I look at the results. Then right at the top of my tree I can see that the first branch/split is based on Group: Colour. To the left I have the value 0 and to the right I have the value 1. Here is what I mean:
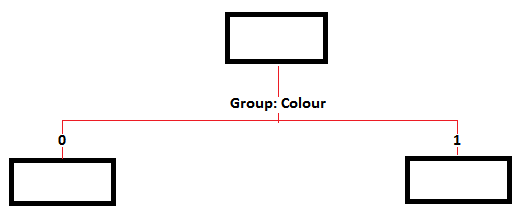
Now the issue I have with this tree (which I hope you can all appreciate) is that I need to go back to the business people that asked for the report and tell them that colour is a significant variable for the car. However, they will ask me what colours, and be looking at this tree I can't tell them which colours are set in 0 and which ones are in the 1.
I looked everywhere for an answer on this but I can't seem to find it. Could someone please advise?
Regards,
P.
Accepted Solutions

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Since you are looking for how to interpret the actual colors in a decision tree model, please note that the tree itself groups those levels automatically so you could make things simple by setting the Use Group Variables property to 'No'. Having said that, the Decision Tree performs Variable Selection anyway so the question might be why you are running the Variable Selection node prior to running the Decision Tree node. This grouping of levels helps Regression and Neural Network models greatly since it limits the necessary number of parameters, but this benefit does not apply to Decision Tree models.
If you do take the approach, please note that the score code generated by SAS Enterprise Miner is intended to be used internally and so there is not an explicit file exported that shows this information. You can see the assignments that are made in the score code output of the Variable Selection node by viewing the Variable Selection node results and then selecting View --> Scoring --> SAS Code which displays the SAS score code that will be passed to the Score node should you add one later in the flow. In my example below, the variable G_JOB was created from the variable JOB which had several levels such as 'MGR', 'OFFICE', 'OTHER', etc...
/*----G_JOB begin----*/
length _NORM7 $ 7;
%DMNORMCP( JOB , _NORM7 )
drop _NORM7;
select(_NORM7);
when(' ' ) G_JOB = 4;
when('MGR' ) G_JOB = 1;
when('OFFICE' ) G_JOB = 3;
when('OTHER' ) G_JOB = 1;
when('PROFEXE' ) G_JOB = 2;
when('SALES' ) G_JOB = 0;
when('SELF' ) G_JOB = 0;
otherwise substr(_WARN_, 2, 1) = 'U';
end;
label G_JOB="Grouped Levels for JOB";
/*----JOB end----*/
I hope this helps!
Doug
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Since you are looking for how to interpret the actual colors in a decision tree model, please note that the tree itself groups those levels automatically so you could make things simple by setting the Use Group Variables property to 'No'. Having said that, the Decision Tree performs Variable Selection anyway so the question might be why you are running the Variable Selection node prior to running the Decision Tree node. This grouping of levels helps Regression and Neural Network models greatly since it limits the necessary number of parameters, but this benefit does not apply to Decision Tree models.
If you do take the approach, please note that the score code generated by SAS Enterprise Miner is intended to be used internally and so there is not an explicit file exported that shows this information. You can see the assignments that are made in the score code output of the Variable Selection node by viewing the Variable Selection node results and then selecting View --> Scoring --> SAS Code which displays the SAS score code that will be passed to the Score node should you add one later in the flow. In my example below, the variable G_JOB was created from the variable JOB which had several levels such as 'MGR', 'OFFICE', 'OTHER', etc...
/*----G_JOB begin----*/
length _NORM7 $ 7;
%DMNORMCP( JOB , _NORM7 )
drop _NORM7;
select(_NORM7);
when(' ' ) G_JOB = 4;
when('MGR' ) G_JOB = 1;
when('OFFICE' ) G_JOB = 3;
when('OTHER' ) G_JOB = 1;
when('PROFEXE' ) G_JOB = 2;
when('SALES' ) G_JOB = 0;
when('SELF' ) G_JOB = 0;
otherwise substr(_WARN_, 2, 1) = 'U';
end;
label G_JOB="Grouped Levels for JOB";
/*----JOB end----*/
I hope this helps!
Doug

Don't miss out on SAS Innovate - Register now for the FREE Livestream!
Can't make it to Vegas? No problem! Watch our general sessions LIVE or on-demand starting April 17th. Hear from SAS execs, best-selling author Adam Grant, Hot Ones host Sean Evans, top tech journalist Kara Swisher, AI expert Cassie Kozyrkov, and the mind-blowing dance crew iLuminate! Plus, get access to over 20 breakout sessions.
Use this tutorial as a handy guide to weigh the pros and cons of these commonly used machine learning algorithms.

Find more tutorials on the SAS Users YouTube channel.
-
1 reply
-
05-13-2013 08:10 AM
-
1238 views
-
0 likes
-
2 in conversation
-
