Why it’s important, how it’s created, and where it’s found
Why is optimized Score code important?
As early as the 1950s, businesses began to recognize the potential benefits of computers. From the demands of commercial enterprise rose the mainframe computer. And the mainframe computers in turn completely revolutionized how businesses operate. Computer development started to accelerate.
In 1962, one of the world's first supercomputers was officially commissioned at Manchester University. The Manchester University Atlas 1 was a joint development between the University of Manchester, Ferranti International PLC, and The Plessey Company PLC. It was considered to be the most powerful computer in the world at that time.
The Manchester Atlas 1 had 96 KB of core storage and 576 KB of virtual memory and could do a floating-point multiply in 4.97 microseconds (4.97e-6 FLOPS). High-level languages used to write programs for the Atlas included Algol 60, FORTRAN and COBOL.
At the time, great care was taken to carefully design and write programs to operate within the constraints of the system. The operating system reserved about 17 KB of the available 96 in core memory. Just try to imagine writing a program to run in a maximum 79KB. The complexity of the problems that were even considered was limited by the resources available to the program. With such constraints, programmers worried about every byte and often every instruction. By necessity, efficiency was the watchword of programming.
In the time between 1962 and now, the available hardware and software has progressed. We now have single systems offering terabytes of core memory and supporting over 120 GFLOPS or 1.2e+14 FLOPS. As the systems grew and the resources available to programmers increased, programs were able to do more and became more and more complex. The constant pressure to manage every byte and instruction gradually eroded. For a lot of practical reasons, the priority of program efficiency became secondary if not eliminated. After all, with seemingly unlimited and constantly increasing resources available, why worry about a few bytes or instructions? Over time, the consideration of program efficiency drew less and less attention. The rules changed.
If only the resources available to programs had expanded since 1962, programmers could easily have rested on their laurels. But snap to the age of BIG DATA! The world's capacity to store information has almost doubled every 3.3 years since the 1980. Some speculate that since 2012, 2.5 exabytes (2.5×1018) of data were created daily. The amount of data available to be processed has now turned back the clock to once again make efficiency of program design and implementation a critical issue for businesses and programmers. The rules have changed again.
Now with the ever-increasing amounts of data available to businesses and governments, even a small efficiency, multiplied by big data, becomes important - even critical.
How does the Score node accumulate and optimize the score code, and how do I save it in a package?
The process of optimizing the Enterprise Miner scoring source code is not applicable to all Enterprise Miner models but most do benefit. To avoid getting too far in to the realm of dragons and magicians, let’s characterize the process of Enterprise Miner (EM) score code accumulation by the Score node.
The Score node back traces the Enterprise Miner flow it is connected to, from end to beginning. Once at the beginning, the process picks up the score code produced by each node in the flow, in order. The Score node can then determine which variables are actually used in the final model. In the Score node results this code is displayed as “SAS Code”. By default the Score node property Optimized Code under Score Code Generation is set to “Yes”, which triggers the Score node to go through all the code it collected from the flow and omit any code that is not related to the variables used by the final model. This results in the code displayed as “Optimized SAS Code” in the Score node results. So in EM whenever possible both the optimized and un-optimized code are produced.
An EM model package doesn’t try to package both types of score code. If your situation requires a package with the non-optimized code, you will need to set the Score node property Optimized Code to “No”; otherwise the package will contain the default “Optimized Score Code”.
A simple illustration using EM can be done in minutes.
- Open EM and a new diagram.
- Create a data source for the SAMPSIO.hmeq data set with a target of BAD.
- Add the data source to the diagram.
- To make the final code less cluttered, in the data source, edit the variables and reject the variables DELINQ, DEROG, JOB, LOAN, MORTDUE, NINQ, and REASON.
- Connect the data source to an Impute node from the Modify tab.
- Connect the Impute node to a Regression node from the Model tab.
- In the Regression node, set the Selection Model property to Stepwise.
- Now add two Score nodes and connect the Regression node to both Score nodes.
- In the Score(2) node, set the Optimized Code property to “No”.
Your diagram should look like this:
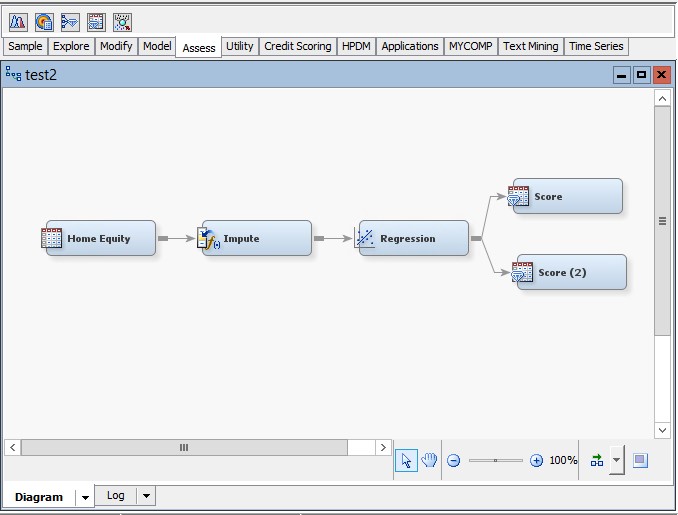
- Now run both Score nodes.
Once you’ve run the Score nodes, open the Results viewer for the first Score node. You can see that the regression model only uses two variables – IMP_CLAGE and IMP_DEBTINC – so the creation of the other imputed variables is not required for the regression model. The code in the Optimized SAS Code window does not contain the calculations for the imputation of the unused input variables VALUE, CLNO, and YOJ.
Optimized SAS Code =
|
*------------------------------------------------------------*;
|
|
* TOOL: Imputation;
|
|
* TYPE: MODIFY;
|
|
* NODE: Impt;
|
|
*------------------------------------------------------------*;
|
|
label IMP_CLAGE = 'Imputed CLAGE';
|
|
IMP_CLAGE = CLAGE;
|
|
if missing(CLAGE) then IMP_CLAGE = 179.76627519;
|
|
label IMP_DEBTINC = 'Imputed DEBTINC';
|
|
IMP_DEBTINC = DEBTINC;
|
|
if missing(DEBTINC) then IMP_DEBTINC = 33.779915349;
|
|
*------------------------------------------------------------*;
|
The code in the SAS Code window includes the calculations to impute all the input variables.
SAS Code =
|
*------------------------------------------------------------*;
|
|
* TOOL: Imputation;
|
|
* TYPE: MODIFY;
|
|
* NODE: Impt;
|
|
*------------------------------------------------------------*;
|
|
*;
|
|
*MEAN-MAX-MIN-MEDIAN-MIDRANGE AND ROBUST ESTIMATES;
|
|
*;
|
|
label IMP_CLAGE = 'Imputed CLAGE';
|
|
IMP_CLAGE = CLAGE;
|
|
if missing(CLAGE) then IMP_CLAGE = 179.76627519;
|
|
label IMP_CLNO = 'Imputed CLNO';
|
|
IMP_CLNO = CLNO;
|
|
if missing(CLNO) then IMP_CLNO = 21.296096201;
|
|
label IMP_DEBTINC = 'Imputed DEBTINC';
|
|
IMP_DEBTINC = DEBTINC;
|
|
if missing(DEBTINC) then IMP_DEBTINC = 33.779915349;
|
|
label IMP_VALUE = 'Imputed VALUE';
|
|
IMP_VALUE = VALUE;
|
|
if missing(VALUE) then IMP_VALUE = 101776.04874;
|
|
label IMP_YOJ = 'Imputed YOJ';
|
|
IMP_YOJ = YOJ;
|
|
if missing(YOJ) then IMP_YOJ = 8.9222681359;
|
|
*------------------------------------------------------------*;
|
Where is optimized Score code found?
If you now create model packages for both score nodes, you will find that the package for the Score node with Optimized = Yes displays the Optimized code. The other package for Score(2) displays the SAS Code with all of the variables imputed.
If saving these files from the Results viewer is too interactive, you can use the Score Code Export node or copy the files from the project files. If you navigate to your project folder and open the Workspaces folder, you should find the diagram folder EMWSn. There you will find the folders for your Score nodes. They are named Score or ScoreN, where N is a number. In the Score folder you will find the code displayed in the Results viewer among many internally used files. The file displayed by the Score node Results viewer as “Optimized SAS Code” is named OPTIMIZEDCODE.sas. The file displayed as “SAS Code” is named PATHPUBLISHSCORECODE.sas.
The other .sas files are really just bits and pieces used internally by EM and should not be used for scoring. For example, the PATHFLOWSCORECODE.sas is code used only in the flow. It does calculations for things potentially useful by nodes that may follow the Score node but not needed in scoring like the residuals.
The Optimized SAS Code can in some circumstances represent a large increase in efficiency. In other circumstances there may be little difference. But by default you get both; Code optimized for the model and code that reflects all of the calculations specified in training the model. The selection of which fits your scoring needs could depend on whether or not your scoring process requires values computed but not used in the EM model.
"The order in which the operations shall be performed in every particular case is a very interesting and curious question, on which our space does not permit us fully to enter. In almost every computation a great variety of arrangements for the succession of the processes is possible, and various considerations must influence the selection amongst them for the purposes of a Calculating Engine. One essential object is to choose that arrangement which shall tend to reduce to a minimum the time necessary for completing the calculation."
~ Augusta Ada King, Countess of Lovelace (1815–1852), English mathematician and writer often described as the world's first computer programmer, known for her work on Charles Babbage's early mechanical general-purpose computer

