- Home
- /
- Programming
- /
- Programming
- /
- Subsetting a dataset for customers with multiple sales regions
- RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
I have a dataset of customer sales with customers and regions. There are only two regions and I'm trying to figure out how to subset my data so I only have customers that have sales in both regions.
My data looks something like this:
| Customer | Region | Sales |
|---|---|---|
| 1 | 2 | 12 |
| 1 | 2 | 14 |
| 1 | 2 | 11 |
| 1 | 2 | 16 |
| 2 | 2 | 15 |
| 2 | 2 | 22 |
| 2 | 6 | 21 |
| 3 | 2 | 14 |
| 3 | 6 | 16 |
| 3 | 6 | 15 |
| 3 | 6 | 14 |
| 3 | 2 | 15 |
| 4 | 6 | 15 |
| 4 | 6 | 11 |
| 4 | 6 | 21 |
| 4 | 6 | 20 |
So basically, in this case, I want to know how I can have a subset of this dataset that will only include customers 2 and 3, since they are the only customers with sales in both regions.
I'm using SAS Enterprise Guide, and I don't know if there is a way to do this using the GUI or if I should use a code node
Thanks!le
Accepted Solutions

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Try this.
proc sql;
create table want as
select * from have
group by customer
having count(distinct region)>1;
quit;
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Do you need all the records or just the id of customer 2/3?
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
I need all the records for those customers
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Try this.
proc sql;
create table want as
select * from have
group by customer
having count(distinct region)>1;
quit;
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
stat@sas,
Perfect! Thank you!
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
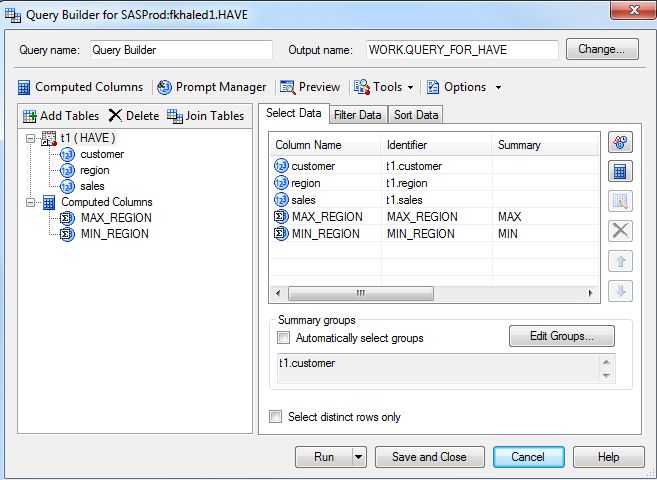
Here's another way with Query Builder. I'd go with code myself ![]()


Don't miss out on SAS Innovate - Register now for the FREE Livestream!
Can't make it to Vegas? No problem! Watch our general sessions LIVE or on-demand starting April 17th. Hear from SAS execs, best-selling author Adam Grant, Hot Ones host Sean Evans, top tech journalist Kara Swisher, AI expert Cassie Kozyrkov, and the mind-blowing dance crew iLuminate! Plus, get access to over 20 breakout sessions.
Learn how use the CAT functions in SAS to join values from multiple variables into a single value.

Find more tutorials on the SAS Users YouTube channel.
 Click image to register for webinar
Click image to register for webinar
Classroom Training Available!
Select SAS Training centers are offering in-person courses. View upcoming courses for:
-
5 replies
-
06-30-2014 04:57 PM
-
560 views
-
3 likes
-
3 in conversation
-
