- Home
- /
- Programming
- /
- Programming
- /
- How to combine empty datasets
- RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
data want;
set have_1 - have_100;
run;
I have 100 datasets, have_1 - have_100 (each have 3 observations and 10 variables), and the order of the datasets is important.
However, some of those 100 datasets are empty which only contain 10 variable names but have no observation.
For example, have_1, have_10, have_23, and have_62 are empty datasets (I don't know which one/s is empty datasets).
The dataset want generated by above code only include 288 observations, and since those 4 empty datasets are not included, the order of the observations in dataset want is now all wrong.
Any options to also merge those 4 empty datasets into dataset want and assign those 4 empty datasets with either 0 or missing value, so that the resulted dataset want will have 300 observation in the original order (of them 12 observations with 0 or missing value)?
Thanks!
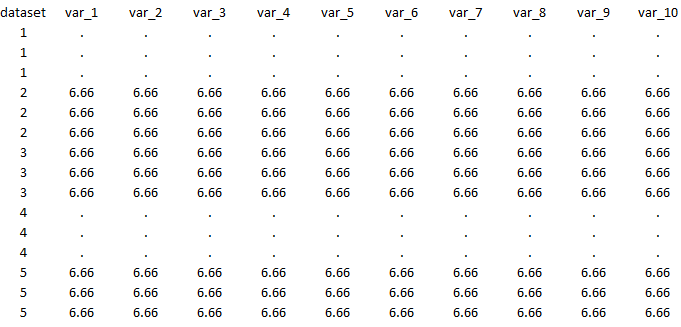
Above is something what I want. If dataset 1 and dataset 4 are not included, then dataset 2 will be the first, dastset 3 then will be 2nd, and datset 5 will be 3rd, etc., that is not what I want.
Accepted Solutions

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
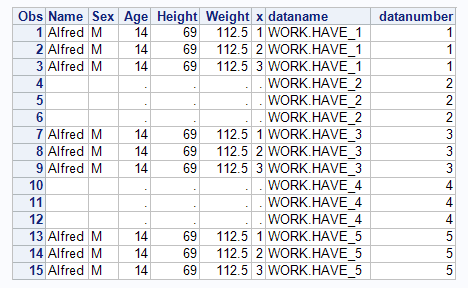
If you want to create a variable with the data set name you can use the INDSNAME option on the set statement. You can also create an index if you like.
set sashelp.class(obs=1);
do x = 1 to 3;
output have_1 have_3 have_5;
end;
run;
proc sql noprint;
select memname into :zero separated by ' '
from dictionary.tables
where libname eq 'WORK' and memname eqt 'HAVE_' and nobs eq 0;
quit;
run;
%put NOTE: &=zero;
data &zero;
do _n_ = 1 to 3;
output;
end;
stop;
set &zero;
run;
data b;
set have_1-have5 open=defer indsname=indsname;
dataname = indsname;
if lag(indsname) ne indsname then datanumber + 1;
run;
proc print;
run;

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
You need to describe how the "order of the observations in dataset want is now all wrong". Also provide an example of what you think should be in the final data set when one of the input sets has 0 observations.
I suspect what you may be asking for is
1) identify the datasets with 0 observations
2) modify those datasets so they have exactly 3 observations with all missing values or all 0 vakyes
3) then append the data.
is that what you're looking for?
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
That is very close to what I thought. my question is now updated. Thanks!
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
I don't think there is any way to detect EOF on individual data sets concatenated in a SET statement but you can "easily" add obs with all missing values to the data with zero obs.
set sashelp.class(obs=1);
do x = 1 to 3;
output a1 a3 a5;
end;
run;
proc sql noprint;
select memname into :zero separated by ' '
from dictionary.tables
where libname eq 'WORK' and memname eqt 'A' and nobs eq 0;
quit;
run;
%put NOTE: &=zero;
data &zero;
do _n_ = 1 to 3;
output;
end;
stop;
set &zero;
*retain _numeric_ 0;
run;
data b;
set a1-a5 open=defer;
run;
proc print;
run;
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Thank you,data_null_; ! I will try this code
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
If you want to create a variable with the data set name you can use the INDSNAME option on the set statement. You can also create an index if you like.
set sashelp.class(obs=1);
do x = 1 to 3;
output have_1 have_3 have_5;
end;
run;
proc sql noprint;
select memname into :zero separated by ' '
from dictionary.tables
where libname eq 'WORK' and memname eqt 'HAVE_' and nobs eq 0;
quit;
run;
%put NOTE: &=zero;
data &zero;
do _n_ = 1 to 3;
output;
end;
stop;
set &zero;
run;
data b;
set have_1-have5 open=defer indsname=indsname;
dataname = indsname;
if lag(indsname) ne indsname then datanumber + 1;
run;
proc print;
run;
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
When I try the code on my datasets, I encountered the following problem. Then I shorten the length of those datasets' name, I found that if dataset's name is longer than 5 characters, then the same problem will occur. e.g. if dataset's name is something like bb_100, then the following problem will occur, if dataset's name is like b_100, then the code works great! (SAS 9.3 TS Level 1M1 in Win7 Enterprise system)
SAS LOG:
121 proc sql noprint;
122 select memname into :zero separated by ' '
123 from
124 dictionary.tables
125 where libname eq 'WORK' and memname eq 'have_m_' and nobs eq 0;
NOTE: No rows were selected.
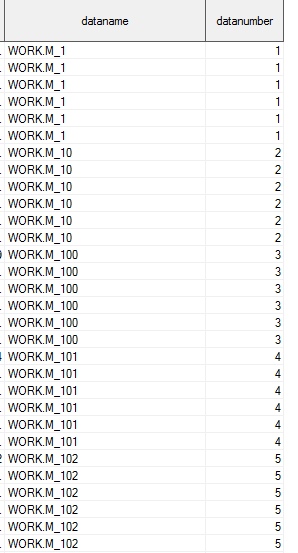
Another problem is that, datasets in work folder are ordered in the way as following showed, anyway to make those datasets in numeric order, so work.M_1 is followed by work.M_2, then work.M_3, only then datanumber=2 will represent work.M_2, rather than work.M_10 as below showed. (or maybe I should first extract numbers from dataname and sort, then generate a new datanumber)
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
This is using the wrong operator MEMNAME EQT 'HAVE_M_'
where libname eq 'WORK' and memname eq 'have_m_' and nobs eq 0;
EQ should be EQT
where libname eq 'WORK' and memname eqT 'have_m_' and nobs eq 0;
For the second problem you will need to use a numeric RANGE in the set statement to get the proper order.
set have_m_1-have_m_102
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Another way to obtain the proper order and still use prefix list HAVE_M_: is to use leading zeros in the number part. 0001 0102 etc.
The advantage of the prefix list is that you don't need to know how many.
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Thanks a lot! the second problem solved by using
set m_1-m_265 open=defer indsname=indsname;
The first question is still there, but I think it is my computer's problem. code will not work if datasets' name with prefix 'have_m_', and it works if I shorten the prefix as 'm_'
SAS LOG
******if dataset name has prefix 'have_m_'
119 proc sql noprint;
120 select memname into :zero separated by ' '
121 from
122 dictionary.tables
123 where libname eq 'WORK' and memname eqt 'have_m_' and nobs eq 0;
NOTE: No rows were selected.
124 quit;
NOTE: PROCEDURE SQL used (Total process time):
real time 0.03 seconds
cpu time 0.04 seconds
******if dataset name has prefix 'm_'
119 proc sql noprint;
120 select memname into :zero separated by ' '
121 from
122 dictionary.tables
123 where libname eq 'WORK' and memname eqt 'm_' and nobs eq 0;
124 quit;
NOTE: PROCEDURE SQL used (Total process time):
real time 0.16 seconds
cpu time 0.17 seconds
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
I did not notice before but you have lower case 'have_m_' the value of MEMNAME is always upper case for SAS data sets. That should get the subset of data sets with zero obs.
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
THANKS! problem solved.
looks like if prefix is 'm_' then lowercase is fine, but if prefix is longer than that, it then must be in uppercase.
133 proc sql noprint;
134 select memname into :zero separated by ' '
135 from
136 dictionary.tables
137 where libname eq 'WORK' and memname eqt 'HAVE_M_' and nobs eq 0;
138 quit;
NOTE: PROCEDURE SQL used (Total process time):
real time 0.18 seconds
cpu time 0.18 seconds

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
SET them all together , and insert the missing table's obs .
data have_1 have_2 have_3 have_4 have_5;
set sashelp.class(obs=1);
do x = 1 to 3;
output have_1 have_5;
end;
run;
data temp(drop=x);
length dsn $ 40 ;
set have_1-have_5 indsname=indsname;
dsn=indsname;
n=input(scan(dsn,-1,'_'),best32.);
run;
data want(drop=n _n i j);
merge temp temp(keep=n rename=(n=_n) firstobs=2);
output;
do i=n+1 to ifn(_n=.,0,_n-1);
dsn=catx('_',scan(dsn,1,'_'),i);
do j=1 to 3;
call missing(name,sex,age,height,weight);
output;
end;
end;
run;
Xia Keshan
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Thank you Ksharp for your idea!

Don't miss out on SAS Innovate - Register now for the FREE Livestream!
Can't make it to Vegas? No problem! Watch our general sessions LIVE or on-demand starting April 17th. Hear from SAS execs, best-selling author Adam Grant, Hot Ones host Sean Evans, top tech journalist Kara Swisher, AI expert Cassie Kozyrkov, and the mind-blowing dance crew iLuminate! Plus, get access to over 20 breakout sessions.
Learn how use the CAT functions in SAS to join values from multiple variables into a single value.

Find more tutorials on the SAS Users YouTube channel.
 Click image to register for webinar
Click image to register for webinar
Classroom Training Available!
Select SAS Training centers are offering in-person courses. View upcoming courses for:
-
13 replies
-
08-14-2014 05:55 PM
-
5889 views
-
8 likes
-
4 in conversation
-
