- Home
- /
- Programming
- /
- Programming
- /
- Re: SPDE vs. disk striping
- RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Hi all,
Most of the benefits of SPDE seem to come from faster I/O as more disks are used concurrently to access data. Other benefits may come from multi-threading, but this is a bit fluffy, and these benefits would kick in only if the CPU was a bottleneck and having more than one CPU process all the data was advantageous. As long as I/O is the bottleneck, which it most often is, I would think that multithreading could actually be disadvantageous as multithreading I/O operations can make them less sequential and therefore slower. I don't doubt that there are cases when more CPU is indeed needed to process all the data arriving from a fast array of disks, but then it is mostly the procedure that uses multithreading, not the data storage.
Anyway, I was wondering ifanyone has tried getting a bunch of disks in to a RAID0 stripe with V9 (or even SPDE) engine data sets, and compared this to keeping the disks as separate volumes and spreading SPDE partitions on these volumes.
One clear advantage of the striping solution is that you don't have numerous small storage spaces to manage, you only have a large volume that is much less likely to fill up. For common tasks such as building an index or reading data, reading from all disks as part of a stripe or reading them through the SPDE engine should yield similar performances, shouldn't it?The stripe is actually more likely to have spread the load more uniformly regardless of the data set size.
Anyone has done the comparison?
Cheers, Chris
PS Ihave come across a few SPDE performance papers, but they never compared SPDE to simply striping.
This one is the closest I could find
http://support.sas.com/resources/papers/proceedings09/263-2009.pdf
but runs V9 vs SPDE engine from a SAN, so not what I want as SANs have many variables that can influence results, and the spread of the data across disks is unknown.
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Having read one happy SPDE user's post on https://communities.sas.com/message/103126#103126, I suspect one valid case for using SDPE would be when you have so much data that large pools of disks are used.
You could then build a bunch of hi-speed arrays, and rather than stripe them again, which might no be possible or may bring no speed benefit or may have management issues, it might then make sense to keep them separate and spread SPDE partitions over them and have threads dedicated to each hi-speed stream of data, since there will be enough data coming in to keep the CPUs busy.
Any thoughts?

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
One conclusion from the limited response for this issue, is that I think most SPDE users just gets a bunch of disk space, specify tha paths for SPDE and hops it works, which in most case it will (i.e. compared to Base SAS engine access).
It's very difficult to give any general advice, there too many parameters that have impact on the performance.
The best is if you have the time and resources to test a few different scenarios in a test environment.
And as you already know, most of it comes down to I/O bandwidth, and communications skills to discuss this with guys handling the file systems.
If you have real performance constraints, it might be best to look at a more configurable solution (i.e. a dedicated database product). If you wish to stay in the SAS sphere that would be SPD Server which gives more options in partitioning the data, and more/better SQL optimization patterns.
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Considering the price of a bay, I would have thought peopel would play a bit with it before they decide on how to use it. Just like acfarrer plans on doing.
As I see it, SPDE may yield a better perf than a stripe due to some cleverer logic than in sas Base, while a stripe will be easier to manage and will always spread the load evenly regardless of dataset size.
Of course one size never fits all, andI was hoping to get varied feedbacks.

- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
We are configuring a new environment with SAS v9.3, RHEL 6.4, GFS2 and hoping to run benchmarks using Direct I/O before the users arrive on the hardware. Some details here: SAS(R) 9.2 Companion for UNIX Environments
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Nice! Looking forward to reading you. ![]()
Will you do DIO tests only? If so any reason for this?
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Any update on your benchmark?
- Mark as New
- Bookmark
- Subscribe
- Mute
- RSS Feed
- Permalink
- Report Inappropriate Content
Each hardware configuration will of course be different, but here is an element of answer, using 4 SSD drives.
A defining characteristic of the SPDE engine is its physical file layout, where the data is partitioned into separate files which can be spread onto separate IO subsystems. This in turn allows two things: each partition can be processed by its own thread, and each partition is served by its own disk.
However, RAID arrays also allow spreading files across multiple disks. So does SPDE’s data partition distribution bring any advantages over just letting a RAID drive do the job of spreading the I/Os? Let’s have a look.
For this test, I’ll describe the testing platform in more details. The other tests were very dependent on the hardware used, but this one even more so. I used a Windows 64 PC with 2 CPUs and 5 disks: One system hard drive and four data SSDs (Intel 320 160GB and 600GB, 2 x Samsung EVO840 120GB).
The metadata will go to the system drive C:, and the data will be spread in different manners for each one of seven tests:
- One data path
- Two data paths pointing to two disks
- Three data paths pointing to three disks
- Four data paths pointing to four disks
- One data path pointing to a 2-disk RAID stripe
- One data path pointing to a 3-disk RAID stripe
- One data path pointing to a 4-disk RAID stripe
This can be seen in the definition of the libraries:
libname ONEDRV spde 'c:\test' datapath=('d:\test' );
libname TWODRV spde 'c:\test' datapath=('d:\test' 'i:\test' );
libname THREEDRV spde 'c:\test' datapath=('d:\test' 'i:\test' 'g:\test' );
libname FOURDRV spde 'c:\test' datapath=('d:\test' 'i:\test' 'g:\test' 'j:\test' );
libname RAID0_2 spde 'c:\test' datapath=('k:\test' );
libname RAID0_3 spde 'c:\test' datapath=('l:\test' );
libname RAID0_4 spde 'c:\test' datapath=('m:\test' );
Now, the test will consist on a pure-write DATA step whereby we create a 5GB table, followed by a pure-read test, and lastly a test where reads and writes take place simultaneously. These three tests are run five times. The data set partitions are the default 128 MB in size.
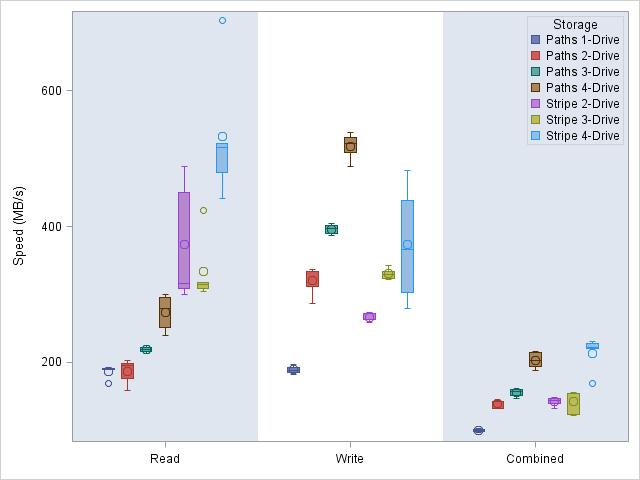
For each test, the bars are dawn left to right in the legend order.
When reading, SPDE improves slightly its performance when 3 or 4 disks are available in its library path. SPDE’s leverage of concatenated-paths libraries is not very convincing though, especially when compared with the huge speed improvements brought by using a RAID array on the same drives.
When writing, the RAID speeds are comparable to their read speed, if a bit lower. SPDE on the other hand is very happy to use the several paths available to it and easily exceeds the RAID speeds.
For the combined read & write operation, the overall speeds are of course much lower. No significant difference can be seen between the solutions that span drives using a RAID array and those that span drives using a concatenated library. This is probably because the lower read and higher write speeds of the SPDE libraries cancel out each other to match the more consistent level of the RAID storage’s speeds.
So does SPDE’s ability to distribute its data bring any benefits? Unfortunately, we can’t assume so from this small test. If your tables are mostly used in read mode, as most data warehouses are, it would definitely pay to do a benchmark before committing to either solution. SPDE’s write speeds are a lot more convincing, but are not as useful.
Another aspect to consider is the geographic and management constraints of the two ways to organise disk space. If the drives are physically scattered, RAID may not be an option. On the other hand, if RAID is an option, it presents the advantage of ease of management: one spacious logical path where all the files are, rather than a collection of paths. Having one fast storage location also presents the advantage that access to other files, such as indexes, metadata files or regular datasets can easily be accelerated as well.
This test is coming from my book:
High-Performance SAS Coding: Christian Graffeuille: 9781512397499: Amazon.com: Books
High-Performance SAS Coding: Polychrome: Christian Graffeuille: 9781514362310: Amazon.com: Books
Just a bit of advertising! ![]()

Don't miss out on SAS Innovate - Register now for the FREE Livestream!
Can't make it to Vegas? No problem! Watch our general sessions LIVE or on-demand starting April 17th. Hear from SAS execs, best-selling author Adam Grant, Hot Ones host Sean Evans, top tech journalist Kara Swisher, AI expert Cassie Kozyrkov, and the mind-blowing dance crew iLuminate! Plus, get access to over 20 breakout sessions.
Learn how use the CAT functions in SAS to join values from multiple variables into a single value.

Find more tutorials on the SAS Users YouTube channel.
 Click image to register for webinar
Click image to register for webinar
Classroom Training Available!
Select SAS Training centers are offering in-person courses. View upcoming courses for:
-
7 replies
-
10-23-2013 08:01 PM
-
1709 views
-
0 likes
-
3 in conversation
-
